# 一、开始
本文讲解 DNS 的基础知识和查询流程,分析递归和迭代的区别,以及尾递归的相关知识。
# 二、DNS
# 1. 概念
DNS 即域名系统,全称是 Domain Name System。当我们在浏览器输入一个 URL 地址时,浏览器要向这个 URL 的主机名对应的服务器发送请求,就得知道服务器的 IP,对于浏览器来说,DNS 的作用就是将主机名转换成 IP 地址。下面是摘自《计算机网络:自顶向下方法》的概念:
DNS 是: 一个由分层的 DNS 服务器实现的分布式数据库 一个使得主机能够查询分布式数据库的应用层协议
什么是分布式?
这个世界上没有一台 DNS 服务器拥有因特网上所有主机的映射,每台 DNS 只负责部分映射。
什么是层次?
DNS 服务器有 3 种类型:根 DNS 服务器、顶级域(Top-Level Domain, TLD)DNS 服务器和权威 DNS 服务器。它们的层次结构如下图所示:

# 2. 域名的层级
www.example.com真正的域名是www.example.com.root,简写为www.example.com.,这里的“.”就是根域名。因为,根域名.root对于所有域名都是一样的,所以平时是省略的。- 根域名的下一级,叫做
"顶级域名"(top-level domain,缩写为TLD),也可称为“一级域名”,比如.com、.net。 - 再下一级叫做
"次级域名"(second-level domain,缩写为SLD),比如www.example.com里面的.example,这一级域名是用户可以注册的。 - 次级域名左侧的,就是
其它级别域名,即最靠近二级域名左侧的字段,从右向左便可依次有三级域名、四级域名、五级域名等,依次类推即可。 - 最左侧的是主机名(
host),比如www.example.com里面的www。
# 3. 本地DNS服务器
本地 DNS 服务器并不属于 DNS 的层次结构,但它对 DNS 层次结构是至关重要的。
每个 ISP(Internet Service Provider,互联网服务提供商) 都有一台本地 DNS 服务器,比如一个居民区的 ISP、一个大学的 ISP、一个机构的 ISP,都有一台或多台本地 DNS 服务器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,本地 DNS 服务器起着代理的作用,并负责将该请求转发到 DNS 服务器层次结构中。
# 三、DNS查询
# 1. 递归查询和迭代查询
假设主机 m.n.com 想要获取主机 a.b.com 的 IP 地址,会经过以下几个步骤:
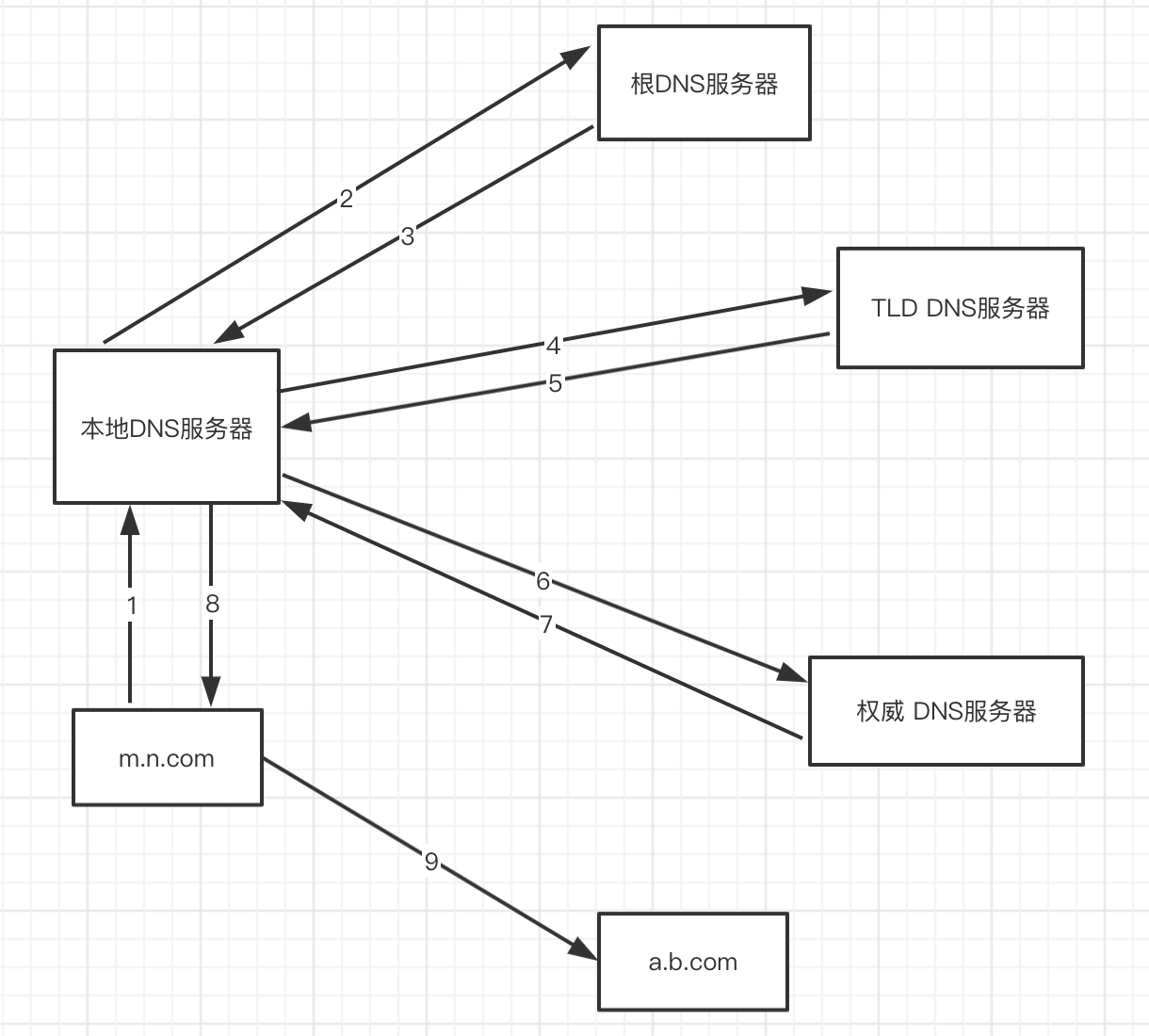
- 首先,主机
m.n.com向它的本地 DNS 服务器发送一个 DNS 查询报文,其中包含期待被转换的主机名a.b.com; - 本地 DNS 服务器将该报文转发到根 DNS 服务器;
- 该根 DNS 服务器注意到
com前缀,便向本地 DNS 服务器返回 com 对应的顶级域 DNS 服务器(TLD)的 IP 地址列表。 意思就是,我不知道a.b.com的 IP,不过这些 TLD 服务器可能知道,你去问他们吧; - 本地 DNS 服务器则向其中一台 TLD 服务器发送查询报文;
- 该 TLD 服务器注意到 b.com 前缀,便向本地 DNS 服务器返回权威 DNS 服务器的 IP 地址。
意思就是,我不知道
a.b.com的 IP,不过这些权威服务器可能知道,你去问他们吧; - 本地 DNS 服务器又向其中一台权威服务器发送查询报文;
- 终于,该权威服务器返回了
a.b.com的 IP 地址; - 本地 DNS 服务器将
a.b.com跟 IP 地址的映射返回给主机m.n.com,m.n.com就可以用该 IP 向a.b.com发送请求啦。
其中,主机 m.n.com 向本地 DNS 服务器 dns.n.com 发出的查询就是递归查询,这个查询是主机 m.n.com 以自己的名义向本地 DNS 服务器请求想要的 IP 映射,并且本地 DNS 服务器直接返回映射结果给到主机。
而后继的三个查询是迭代查询,包括本地 DNS 服务器向根 DNS 服务器发送查询请求、本地 DNS 服务器向 TLD 服务器发送查询请求、本地 DNS 服务器向权威 DNS 服务器发送查询请求,所有的请求都是由本地 DNS 服务器发出,所有的响应都是直接返回给本地 DNS 服务器。
# 2. DNS 记录的类型
域名与IP之间的对应关系,称为"记录"(record)。根据使用场景,"记录"可以分成不同的类型(type)。
常见的DNS记录类型如下:
- A:地址记录(Address),返回域名指向的IP地址。
- NS:域名服务器记录(Name Server),返回保存下一级域名信息的服务器地址。该记录只能设置为域名,不能设置为IP地址。
- MX:邮件记录(Mail eXchange),返回接收电子邮件的服务器地址。
- CNAME:规范名称记录(Canonical Name),返回另一个域名,即当前查询的域名是另一个域名的跳转。
- PTR:逆向查询记录(Pointer Record),只用于从IP地址查询域名。
# 3. DNS 查询相关命令
# (1)dig 命令
- 显示 DNS 查询的整个过程
dig <域名>
# 比如
dig baidu.com
- 显示 DNS 分级查询过程
dig +trace <域名>
# 比如
dig +trace baidu.com
dig命令可以单独查看每一级域名的 NS 记录
比如
dig ns <分级域名>
# 比如
dig ns com
dig ns baidu.com
dig 后面的的 ns 可以换成其他的DNS记录类型,比如 a、mx。
$ dig a github.com
$ dig ns github.com
$ dig mx github.com
+short 参数可以显示简化的结果
$ dig +short ns com
$ dig +short ns baidu.com
dig命令加上-x可以从IP地址反查域名
比如:
$ dig -x 220.181.38.251
# (2)host 命令
host 命令可以看作 dig 命令的简化版本,返回当前请求域名的各种记录。
$ host baidu.com
host 命令也可以用于逆向查询,即从 IP 地址查询域名,等同于 dig -x <ip>。
$ host 220.181.38.251
# (3)nslookup 命令
nslookup 命令用于互动式地查询域名记录。
$ nslookup
# 四、递归和迭代
# 1. 概念
递归是一个树结构,从字面可以其理解为重复“递推”和“回归”的过程,当“递推”到达底部时就会开始“回归”,其过程相当于树的深度优先遍历。
迭代是一个环结构,从初始状态开始,每次迭代都遍历这个环,并更新状态,多次迭代直到到达结束状态。
相同点:递归和迭代都是循环的一种。
不同点:
程序结构不同
- 递归是重复调用函数自身实现循环。
- 迭代是函数内某段代码实现循环。
- 其中,迭代与普通循环的区别是:迭代时,循环代码中参与运算的变量同时是保存结果的变量,当前保存的结果作为下一次循环计算的初始值。
算法结束方式不同
- 递归循环中,遇到满足终止条件的情况时逐层返回来结束。
- 迭代则使用计数器结束循环。
- 当然很多情况都是多种循环混合采用,这要根据具体需求。
效率不同
- 在循环的次数较大的时候,迭代的效率明显高于递归。因为,大量的递归调用会建立函数的副本,会耗费大量的时间和内存。而迭代则不需要反复调用函数和占用额外的内存。
# 2. 实例
(1)计算 n!
// 递归
function fa(n) {
if (n == 1) {
return 1;
}
return n * fa(n - 1);
}
// 迭代
function fa2(n) {
let res = 1;
for (let i = 1; i < n + 1; i++) {
res = res * i;
}
return res;
}
(2)斐波那契数列
// 递归
function fn(n) {
if (n <= 2) {
return 1;
}
return fn(n - 2) + fn(n - 1);
}
// 迭代
function fn2(n) {
const list = [1, 1, 2, 3];
for (let i = 2;i < n;i++) {
list[i] = list[i - 2] + list[i - 1];
}
return list[n - 1];
}
看了递归和迭代的概念和例子,再去理解 DNS 的递归查询和迭代就简单多了。
# 3. 尾调用优化
尾调用(Tail Call)是函数式编程的一个重要概念,是指某个函数的最后一步是调用另一个函数,比如:
function f(x){
return g(x);
}
函数调用会在内存形成一个“调用记录”,又称“调用帧”(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用帧上方,还会形成一个B的调用帧。等到B运行结束,将结果返回到A,B的调用帧才会消失。如果函数B内部还调用函数C,那就还有一个C的调用帧,以此类推。所有的调用帧,就形成一个“调用栈”(call stack)。
尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用帧,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用帧,取代外层函数的调用帧就可以了。
function f() {
let m = 1;
let n = 2;
return g(m + n);
}
f();
// 等同于
function f() {
return g(3);
}
f();
// 等同于
g(3);
上面代码中,如果函数g不是尾调用,函数f就需要保存内部变量m和n的值、g的调用位置等信息。但由于调用g之后,函数f就结束了,所以执行到最后一步,完全可以删除f(x)的调用帧,只保留g(3)的调用帧。
这就叫做“尾调用优化”(Tail call optimization),即只保留内层函数的调用帧。如果所有函数都是尾调用,那么完全可以做到每次执行时,调用帧只有一项,这将大大节省内存。
# 4. 尾递归
函数调用自身,称为递归。如果尾调用自身,就称为尾递归。
递归非常耗费内存,因为需要同时保存成千上百个调用帧,很容易发生“栈溢出”错误(stack overflow)。但对于尾递归来说,由于只存在一个调用帧,所以永远不会发生“栈溢出”错误。
function factorial(n) {
if (n === 1) return 1;
return n * factorial(n - 1);
}
factorial(5) // 120
上面代码是一个阶乘函数,计算n的阶乘,最多需要保存n个调用记录,复杂度 O(n) 。
如果改写成尾递归,只保留一个调用记录,复杂度 O(1) 。
function factorial(n, total = 1) {
if (n === 1) return total;
return factorial(n - 1, n * total);
}
factorial(5) // 120
还有一个比较著名的例子,就是计算 Fibonacci 数列,也能充分说明尾递归优化的重要性。
非尾递归的 Fibonacci 数列实现如下。
function Fibonacci (n) {
if ( n <= 1 ) {return 1};
return Fibonacci(n - 1) + Fibonacci(n - 2);
}
Fibonacci(10) // 89
Fibonacci(100) // 超时
Fibonacci(500) // 超时
尾递归优化过的 Fibonacci 数列实现如下。
function Fibonacci2 (n , ac1 = 1 , ac2 = 1) {
if( n <= 1 ) {return ac2};
return Fibonacci2 (n - 1, ac2, ac1 + ac2);
}
Fibonacci2(100) // 573147844013817200000
Fibonacci2(1000) // 7.0330367711422765e+208
Fibonacci2(10000) // Infinity