# 一、编码与解码
计算机程序信息都是以二进制形式存储,也就是说我们在代码中定义的一个char字符或者一个int整数都会被转换成二进制码储存起来,这个过程可以被称为编码,而将计算机底层的二进制码转换成屏幕上有意义的字符(如hello world),这个过程就称为解码。
编解码会涉及到字符集(Character Set) 这个概念,他就相当于能够将一个字符与一个整数一一对应的一个映射表,常见的字符集有ASCII、Unicode等。
# 二、ASCII 码
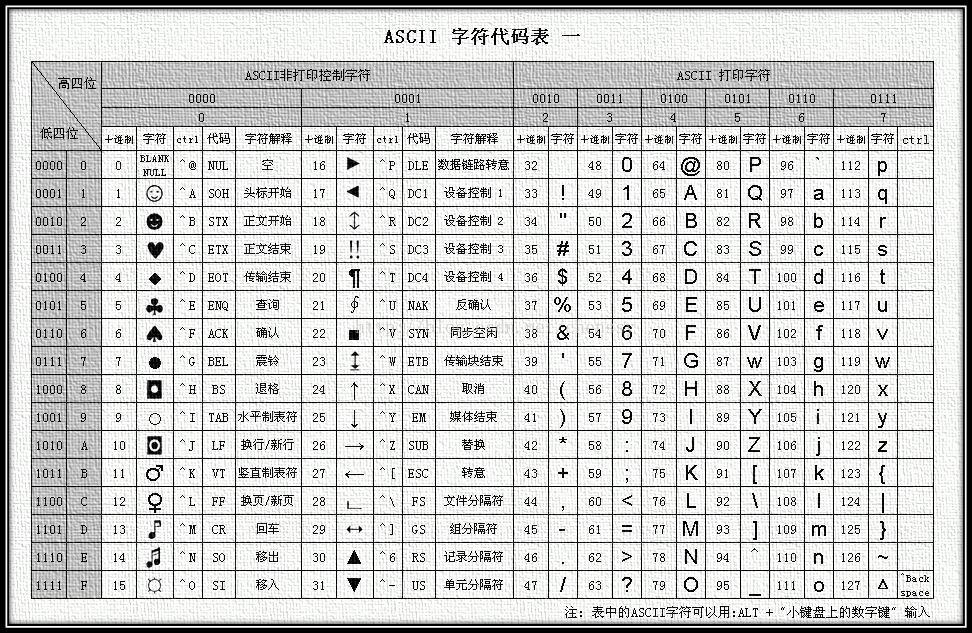
ASCII (American Standard Code for Information Interchange),美国信息交换标准代码是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
ASCII 码一共规定了128个字符的编码,比如空格SPACE是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
# 三、Unicode
# 1. 概念
Unicode,也叫统一码、万国码、单一码,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
Unicode 兼容 ASCII,即0~127意义依然不变。
Unicode 用数字0-0x10FFFF来映射世界上的字符,最多可以容纳1114112个字符,或者说有1114112个码位。码位就是可以分配给字符的数字。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
# 2. 码点
它从0开始,为每个符号指定一个编号,这叫做"码点"(code point)。比如,码点0的符号就是null(表示所有二进制位都是0)。
U+0000 = null
U+597D = 好
上式中,U+表示紧跟在后面的十六进制数是Unicode的码点。
Unicode分区定义这些符号。每个区可以存放65536个(2^16)字符,称为一个平面(plane)。目前,一共有17(2^5)个平面,整个Unicode字符集的大小现在是2^21,但是现在用到的是65536*17=1114112个码位。
最前面的65536个字符位,称为基本多语言平面(Basic Multilingual Plane,即BMP),它的码点范围是从0一直到2^16-1,写成16进制就是从U+0000到U+FFFF。所有最常见的字符都放在这个平面,这是Unicode最先定义和公布的一个平面。
剩下的字符都放在辅助平面(Supplementary Planes,即SP),码点范围从U+010000一直到U+10FFFF。
0000-FFFF:基本平面
10000–1FFFF:第1辅助平面
20000–2FFFF:第2辅助平面
30000–3FFFF:第3辅助平面
40000–DFFFF:第4-13辅助平面
E0000–EFFFF:第14辅助平面
F0000–FFFFF:第15辅助平面
100000–10FFFF:第16辅助平面
# 3. iconfont
大部分编码都有其固定作用,比如『中日韩统一表意文字』的码位范围就在:4E00 - 9FFF,共包含 20992 个字符,可以显示大多数中文文字。
但 unicode 留出了一个『私用区』可以用来进行字体扩展,大部分 iconfont 也都默认使用了这一区域。这一区域的码值范围是:E000 - F8FF,所以你会看到 font awesome 的编码从 F000 开始,iconmoon 从 E900 开始,阿里 从 E000 开始。
如果把图标编码设置为 5 位的或者不在私用区范围以内的,就会侵占其他的一些码段,使得使用该字体时无法正确显示其他的字体。比如你占用了 77E5 这个码,那么用了这个字体之后你就显示不出知乎的『知』字了。
# 四、编码方式
Unicode只是指定了字符集,也就是每个字符的码点,到底用什么样的字节序表示这个码点,就涉及到编码方法。
# 1. UTF-32
每个码点使用四个字节表示,字节内容一一对应码点。这种编码方法就叫做UTF-32(Universal Character Set/Unicode Transformation Format)。
U+0000 = 0x0000 0000 = 00000000 00000000 00000000 00000000
U+597D = 0x0000 597D = 00000000 00000000 01011001 01111101
UTF-32的优点在于,转换规则简单直观,查找效率高。缺点在于浪费空间,同样内容的英语文本,它会比ASCII编码大四倍。
# 2. UTF-8
UTF-8是一种变长的编码方法,字符长度从1个字节到4个字节不等。越是常用的字符,字节越短,最前面的128个字符,只使用1个字节表示,与ASCII码完全相同。
UTF-8 的编码规则很简单,只有二条:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
- 对于n字节的符号(
n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
Unicode符号范围 | 码点范围 | UTF-8编码方式
(十六进制) | (十进制) |(二进制)
--------------------+-----------------------------------------------
0000 0000-0000 007F | 0 - 127 | 0xxxxxxx
0000 0080-0000 07FF | 128 - 2047 | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 2048 - 65535 | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 65536 - 1114111 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
上面的字母x表示可用编码的位。
根据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,以汉字严为例,演示如何实现 UTF-8 编码。
严的 Unicode 是4E25(1001110 00100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。
# 3. UTF-16
UTF-16是一种变长的编码方法,长度为2个字节或4个字节。
基本平面的字符占用2个字节,辅助平面的字符占用4个字节。也就是说,UTF-16的编码长度要么是2个字节(U+0000到U+FFFF),要么是4个字节(U+010000到U+10FFFF)。
在基本平面内,从U+D800到U+DFFF是一个空段,即这些码点不对应任何字符。因此,这个空段可以用来映射辅助平面的字符。
具体来说,辅助平面的字符位共有2^20个,也就是说,对应这些字符至少需要20个二进制位。UTF-16将这20位拆成两半,前10位映射在U+D800到U+DBFF(空间大小2^10),称为高位(H),后10位映射在U+DC00到U+DFFF(空间大小2^10),称为低位(L)。这意味着,一个辅助平面的字符,被拆成两个基本平面的字符表示。
辅助平面字符的转码公式:
H = Math.floor((c-0x10000) / 0x400)+0xD800
L = (c - 0x10000) % 0x400 + 0xDC00
以字符𝌆为例,它是一个辅助平面字符,码点为U+1D306,将其转为UTF-16的计算过程如下。
H = Math.floor((0x1D306-0x10000)/0x400)+0xD800 = 0xD834
L = (0x1D306-0x10000) % 0x400+0xDC00 = 0xDF06
所以,字符𝌆的UTF-16编码就是0xD834 DF06,长度为四个字节。
# 五、JS编码
# 1. USC-2
JS使用的编码方式是USC-2,就是不完备的UTF-16,使用2个字节表示所有字符,所有字符都是2个字节,如果是4个字节的字符,会当作两个双字节的字符处理。
以字符𝌆为例,它的UTF-16编码是4个字节的0xD834 DF06。问题来了,4个字节的编码不属于UCS-2,JavaScript不认识,只会把它看作单独的两个字符U+D834和U+DF06。前面说过,这两个码点是空的,所以JavaScript会认为是两个空字符组成的字符串。
console.log('𝌆'.length)
// 2
console.log('𝌆' === '\u1D306')
// false
console.log('𝌆'.charAt(0))
// �
console.log('𝌆'.charCodeAt(0))
// 55348(0xD834)
上面代码表示,JavaScript认为字符的长度是2,取到的第一个字符是空字符,取到的第一个字符的码点是0xDB34。这些结果都不正确!
String.length方法计算的长度单位是“代码单元”,即code unit,有的地方称为“码元”,就是2个字节。
# 2. ES6
ES6增强了对Unicode的支持:
for of遍历会以码点为单位\u{}的方式表示4个字节的码点,比如\u{1D306}fromCodePoint/codePointAt等APIu修饰符正则支持,比如/^.$/u.test('𝌆')normalize方法
# 3. 相关API
😂,码点是U+1F602,10进制是128514。
# (1)String.prototype.codePointAt()
返回一个 Unicode 编码点值的非负整数。
比如
console.log('😂'.codePointAt())
// 128514
console.log('😂'.codePointAt(0))
// 128514
console.log('😂'.codePointAt(1))
// 56834
console.log('😂'.codePointAt(2))
// undefined
console.log('😂a'.codePointAt(2))
// 97
# (2)String.prototype.charCodeAt()
返回 0 到 65535 之间的整数,表示给定索引处的 UTF-16 代码单元
如果 Unicode 码点不能用一个 UTF-16 编码单元表示(因为它的值大于0xFFFF),则所返回的编码单元会是这个码点代理对的第一个编码单元) 。如果你想要整个码点的值,使用 codePointAt()。
比如:
console.log('😂a'.charCodeAt())
// 55357
console.log('😂a'.charCodeAt(0))
// 55357
console.log('😂a'.charCodeAt(1))
// 56834
console.log('😂a'.charCodeAt(2))
// 97
console.log('😂a'.charCodeAt(3))
// NaN
# (3)String.prototype.charAt()
返回一个新字符串,该字符串由位于字符串中指定偏移处的单个UTF-16代码单元组成。
参数为index,表示字符串的下标索引,默认为0。
比如:
console.log('😂a'.charAt())
// �
console.log('😂a'.charAt(0))
// �
console.log('😂a'.charAt(1))
// �
console.log('😂a'.charAt(2))
// a
可以看到由于😂的码点大于65536,当获取第一个代码单元,并将它转为字符时失败,用�表示。
�这个符号的码点是U+FFFD(65533),也就是在基本面的最后上了车。
# (4)String.fromCodePoint()
使用指定的码点序列创建的字符串。
使用格式为:
String.fromCodePoint(num1)
String.fromCodePoint(num1, num2)
String.fromCodePoint(num1, num2, ..., numN)
比如:
String.fromCodePoint(65536, 65535, 65534, 65533, 128514)
// 𐀀�😂
String.fromCodePoint(26446, 23567, 40857)
// 李小龙
# (5)String.fromCharCode()
返回从指定的 UTF-16 代码单元序列创建的字符串。
使用格式为:
String.fromCharCode(num1)
String.fromCharCode(num1, num2)
String.fromCharCode(num1, num2, ..., numN)
注意num范围在0和65535(0xFFFF)之间 。大于的数字0xFFFF被截断。不执行有效性检查。
比如:
console.log(String.fromCharCode(65, 66, 67));
// returns "ABC"
console.log(String.fromCharCode(0x2014));
// returns "—"
console.log(String.fromCharCode(0x12014));
// also returns "—"; the digit 1 is truncated and ignored
console.log(String.fromCharCode(8212));
// also returns "—"; 8212 is the decimal form of 0x2014
# 4. JS/HTML/CSS的Unicode编码
- JavaScript:
'\u5b89' - HTML:
安。HTML还可以转换为10进制:安 - CSS:
'\5b89'