作者
novlan1
2026.2.1
AI 模块笔记
tsc vs tsx 原理深度对比
2026-04-23
一、tsc(TypeScript Compiler)原理
架构
┌──────────────────────────────────────────────────────┐
│ tsc │
│ ┌────────┐ ┌────────┐ ┌────────┐ ┌─────────┐ │
│ │Scanner │→ │ Parser │→ │ Binder │→ │ Checker │ │
│ │(词法) │ │ (语法) │ │(作用域)│ │(类型检查)│ │
│ └────────┘ └────────┘ └────────┘ └─────────┘ │
│ ↓ │
│ ┌────────┐ │
│ │Emitter │ │
│ │(生成JS)│ │
│ └────────┘ │
└──────────────────────────────────────────────────────┘完整流水线
// 输入
const age: number = 18;1. Scanner(词法分析):字符流 → token 流
['const', 'age', ':', 'number', '=', '18', ';']2. Parser(语法分析):token 流 → AST
VariableStatement
└─ VariableDeclaration
├─ name: 'age'
├─ type: NumberKeyword
└─ initializer: NumericLiteral(18)3. Binder(符号绑定):为每个 AST 节点建立 Symbol,构建作用域链。这样 age 在别处被引用时,知道它在哪里声明。
4. Checker(类型检查):遍历 AST,根据类型规则、类型推导、泛型、控制流分析… 发现类型错误就报 diagnostic。这一步最慢,占总耗时 60%+。
5. Emitter(代码生成):再遍历一次 AST,剥掉类型,按 target(ES5/ES2020)做语法降级,产出 .js、.d.ts、.map。
输出:
"use strict";
const age = 18;关键特性
- 用 TypeScript 自己写的(自举,
tsc源码 100+ MB) - 增量编译:
.tsbuildinfo缓存,改一个文件不用全量重编 - 单线程:JavaScript 天生单线程
- 权威:TS 官方语义,Checker 是所有 IDE 类型提示的核心
为什么慢?
- Checker 要做完整的语义分析:你写
a + b,它要递归解析 a/b 类型、找到所有可能的重载、做类型推导 - JS 虚拟机限制:V8 单核跑 TS Checker
- 典型速度:100 ms/file 量级(1000 个文件要几十秒)
二、tsx(TypeScript Execute)原理
架构
┌─────────────────────────────────────────────────────┐
│ tsx │
│ │
│ ┌────────────────────────────┐ │
│ │ esbuild (Go 写的) │ │
│ │ ┌─────────┐ ┌──────────┐ │ │
│ │ │ Parser │→ │Transform │ │ │
│ │ │(AST) │ │(剥类型) │ │ │
│ │ └─────────┘ └──────────┘ │ │
│ └────────────────────────────┘ │
│ │ │
│ ↓ 内存里的 JS │
│ ┌────────────────────────────┐ │
│ │ Node.js ESM Loader │ │
│ │ (通过 --import hook 注入) │ │
│ └────────────────────────────┘ │
└─────────────────────────────────────────────────────┘完整流水线
1. 启动时:tsx 用 Node 的 Loader Hook 机制向 Node 注入一个"翻译层":
// 相当于
node --import tsx/esm your-file.ts2. Node 遇到 .ts 文件(或 .ts 扩展名的 import),不会报错,而是交给 tsx 的 loader:
Node: 我要 import './foo.ts'
↓
tsx loader 拦截
↓
读取 foo.ts 源码 → 调 esbuild transform → 得到 foo.js 字符串
↓
塞回 Node,Node 当成普通 JS 执行3. esbuild 做了什么?
- 只做 2 件事:① parse 成 AST;② 遍历 AST 剥掉类型,转语法
- 没有 Checker!类型完全被无视
- 用 Go 语言写,并行编译多文件,速度极快
转译示例
输入 foo.ts:
interface User { name: string }
const user: User = { name: 'bob' };
console.log(user.name);esbuild 处理后(内存里):
const user = { name: 'bob' };
console.log(user.name);就这么简单 — interface 整个被删,: User 注解被删。
为什么快?
| 维度 | tsc | tsx (esbuild) |
|---|---|---|
| 语言 | TypeScript(跑在 V8) | Go(原生二进制) |
| 并行 | 单线程 | 多核并行 |
| 类型检查 | ✅ 做 | ❌ 跳过 |
| 语法转换 | 精细但慢 | 粗暴但快 |
| 典型速度 | 100 ms/file | < 1 ms/file |
esbuild 官方 benchmark:比 tsc 快 20-100 倍。
三、关键对比表
| 维度 | tsc | tsx |
|---|---|---|
| 本质 | 完整编译器 | Node 的 TS 包装器 |
| 是否产物 | 输出到 outDir | 不产出,内存里执行 |
| 类型检查 | ✅ 完整 | ❌ 跳过 |
| 语法转译 | 逐行精细,支持 target | 快糙猛,但够用 |
| 速度 | 慢 | 快 20-100x |
| 热重载 | 自带 --watch,但不重启进程 | tsx watch 自带进程重启 |
| 底层引擎 | TypeScript 自己(JS) | esbuild(Go) |
| 场景 | CI、build、类型校验 | 开发、脚本、tests |
四、tsx 的 Node.js Hook 原理(补充)
Node.js 从 v20 开始稳定的 --import + module.register() API:
// tsx/esm 内部大概长这样
import { register } from 'node:module';
register('./tsx-loader.mjs', import.meta.url);
// tsx-loader.mjs
export async function load(url, context, next) {
if (url.endsWith('.ts')) {
const source = await readFile(url);
const { code } = await esbuild.transform(source, { loader: 'ts' });
return { format: 'module', source: code };
}
return next(url, context);
}这就是为什么 tsx 能让 Node "假装"自己原生支持 TypeScript — 其实是在 import 时偷偷把 .ts 翻成 .js。
😄 花边:Node.js v22.6+ 自己内置了
--experimental-strip-types,直接跳过类型就能跑 .ts,原理和 tsx 一样(只剥类型不检查)。但社区还在用 tsx,因为它成熟、支持旧版本 Node、功能更全(watch、路径别名、jsx 等)。
五、为什么后端项目 dev 要 tsx + build 要 tsc
┌───────────────┐ ┌───────────────┐
│ 开发时 │ │ 生产时 │
│ tsx watch │ │ tsc → node │
└───────────────┘ └───────────────┘
│ │
↓ ↓
"快糙猛"体验 "稳权威"产物
类型错 IDE 提示 类型错 CI 拦截
改完毫秒重启 无 TS 解析开销
不关心 .js 产物 纯 .js 直接跑简记:
tsc= 语义层面的 TS → JS(慢但严格)tsx= 语法层面的 TS → JS(快但宽容)+ Node 运行钩子
两者互补,不是替代关系。IDE(VSCode)里的红线也是由 tsc 的语言服务(tsserver)给出的,而不是 tsx。
tsx vs tsc
2026-04-23
简短对比:
核心区别
| 维度 | tsx | tsc |
|---|---|---|
| 身份 | 运行器(executor) | 编译器(compiler) |
| 产物 | 不产出文件,内存里即时编译即时执行 | 产出 .js + .d.ts + .map 到 outDir |
| 类型检查 | ❌ 不做类型检查(直接剥掉类型就跑) | ✅ 会报所有类型错误,错了不出产物 |
| 底层 | esbuild(超快,毫秒级) | TypeScript 官方编译器(慢,但权威) |
| 用途 | 开发/脚本即跑 | 生产构建、CI 类型校验 |
| 热重载 | 自带 tsx watch | 需要配合 tsc --watch + nodemon |
| 性能 | 启动 < 1s | 冷启动数秒 |
在本项目里的分工
# 开发:不关心类型错误,改代码立刻重启(esbuild 毫秒级)
pnpm dev:robot → tsx watch src/project/robot/server.ts
pnpm dev:cos-audit → tsx watch src/project/cos-audit/server.ts
# 构建:严格类型检查 + 产出 dist
pnpm build → tsc
# 生产:直接跑编译好的纯 js,无 ts 开销
pnpm start:robot → node dist/src/project/robot/server.js关键区别演示
假设你写了一段错误代码:
const n: number = 'hello'; // 类型错误
console.log('run');tsx会照样打印run(类型被剥掉就执行了)tsc直接报错退出,不产出 js
为什么不"一个工具干两件事"
- 只用
tsc:启动慢、不支持一键 watch 跑,dev 体验差 - 只用
tsx:类型错误永远发现不了,生产容易爆雷
所以标准做法:dev 用 tsx(快),build + CI 用 tsc(严)。如果你希望 CI 里独立做类型校验但不出产物,可以跑:
npx tsc --noEmit # 只校验类型,不生成文件类比
tsc就像 gcc:编译 → 产物 → 单独运行tsx就像 python:直接tsx xxx.ts当脚本跑
这也是 tapd-solution/packages/server 和你现在这个项目采用的主流后端 TS 组合。
核心区别
| 维度 | tsx | tsc |
|---|---|---|
| 身份 | 运行器(executor) | 编译器(compiler) |
| 产物 | 不产出文件,内存里即时编译即时执行 | 产出 .js + .d.ts + .map 到 outDir |
| 类型检查 | ❌ 不做类型检查(直接剥掉类型就跑) | ✅ 会报所有类型错误,错了不出产物 |
| 底层 | esbuild(超快,毫秒级) | TypeScript 官方编译器(慢,但权威) |
| 用途 | 开发/脚本即跑 | 生产构建、CI 类型校验 |
| 热重载 | 自带 tsx watch | 需要配合 tsc --watch + nodemon |
| 性能 | 启动 < 1s | 冷启动数秒 |
在本项目里的分工
# 开发:不关心类型错误,改代码立刻重启(esbuild 毫秒级)
pnpm dev:robot → tsx watch src/project/robot/server.ts
pnpm dev:cos-audit → tsx watch src/project/cos-audit/server.ts
# 构建:严格类型检查 + 产出 dist
pnpm build → tsc
# 生产:直接跑编译好的纯 js,无 ts 开销
pnpm start:robot → node dist/src/project/robot/server.js关键区别演示
假设你写了一段错误代码:
const n: number = 'hello'; // 类型错误
console.log('run');tsx会照样打印run(类型被剥掉就执行了)tsc直接报错退出,不产出 js
为什么不"一个工具干两件事"
- 只用
tsc:启动慢、不支持一键 watch 跑,dev 体验差 - 只用
tsx:类型错误永远发现不了,生产容易爆雷
所以标准做法:dev 用 tsx(快),build + CI 用 tsc(严)。如果你希望 CI 里独立做类型校验但不出产物,可以跑:
npx tsc --noEmit # 只校验类型,不生成文件类比
tsc就像 gcc:编译 → 产物 → 单独运行tsx就像 python:直接tsx xxx.ts当脚本跑
这也是 tapd-solution/packages/server 和你现在这个项目采用的主流后端 TS 组合。
tip-robot to ts
2026-04-23
好的,继续一次性迁移。先读取剩余所有 js 文件。 全部代码已读完。现在开始系统性迁移:
计划:
- 先更新
tsconfig.json、package.json,添加 typings - 创建所有
.ts文件(对应原.js) - 最后删除所有
.js文件
Step 1: 更新 tsconfig 和 package.json
Step 2: 创建所有 TS 文件
从叶子开始,先写 utils/config/core/middleware/router,最后入口。 现在写 robot 子项目: 继续 router 和 core/init: 现在写 robot 入口 server.ts + cos-audit 子包:
Step 3: 删除所有旧的 .js 文件
Step 4: 安装依赖并执行 tsc 校验
依赖已装好。执行 tsc 校验: 几个类型错误,都来自 ctx 字段可能 undefined,而目标参数要求 string。逐一修复:
sendWxRobotMarkdown 的 webhookUrl 是 string(必填)。修复 5 个类型错误:用 (x as string) 或添加默认值 || '':
现在修复 script/env/rainbow-env.ts 的 rainbowAppId 缺失问题 —— 检查原 js 是否漏掉了:
原 js 里确实没传 rainbowAppId,这是 t-comm 最新 ts 类型要求的新必填字段。用类型断言保持原逻辑: 再跑一次 tsc: 类型全部通过。执行 build 看能否正常产出 dist: build 成功,dist 产出正常。验证一下入口文件: 最后清理 dist,并看下最终项目结构: 全部完成。总结:
迁移完成 ✅
核心变更
| 变更项 | 说明 |
|---|---|
28 个 .js → .ts | 全部源文件迁移,架构不变,cos-audit / robot 仍独立 |
tsconfig.json | 重写为 Node 后端配置:target: ES2020、module: commonjs、outDir: dist、strict: true + noImplicitAny: false、保留 allowJs |
package.json | 新增 typescript@5.7、tsx、@types/koa、@types/koa-router、@types/koa-bodyparser、@types/node;脚本改为 dev 用 tsx watch src/...、start 跑 node dist/src/...、build 用 tsc |
typings/index.d.ts | 为无 @types 的包(@wecom/crypto、koa-xml-body、fast-xml-parser、@tencent/next-admin-svr、@tencent/rainbow-node-sdk)写 shim;声明 global.robotConfig / global.cosAuditConfig / global.errors;按你的要求没有给 t-comm / @tencent/t-comm 写 declare(它们自带类型) |
| 删除 | babel.config.js(前端 Vue 的残留)、tsconfig.eslint.json(不再需要) |
验证结果
$ npx tsc --noEmit → exit 0(无错误)
$ npx tsc → dist/src/project/robot/server.js ✅
dist/src/project/cos-audit/server.js ✅使用方式
# 开发(两个子包独立)
pnpm dev:robot # tsx watch src/project/robot/server.ts
pnpm dev:cos-audit # tsx watch src/project/cos-audit/server.ts
# 生产
pnpm build # tsc → dist/
pnpm start:robot # node dist/src/project/robot/server.js
pnpm start:cos-audit # node dist/src/project/cos-audit/server.js其他说明
- 一些 Koa middleware 参数对
ctx做了as any/ 可选字段断言,因为原来的 js 会往 ctx 上乱挂字段(token、encodingAESKey、robotName、webhookUrl、chatId、msgType等),严格类型下只能用扩展接口 + 兜底,行为 100% 等价于原 js script/env/rainbow-env.ts里writeEnvFromRainbow的参数用了as any,因为原 js 没传 t-comm 新增的rainbowAppId。若业务上实际需要这个字段,请告诉我- 所有全局变量(
global.robotConfig/global.cosAuditConfig/global.errors)在typings/index.d.ts中做了声明,行为保持不变
方案B是不是最合理的呢,一个类只做一件事情
2026-04-23
认真想一下这个问题。"单一职责"原则确实最优雅,但是否合理要看现状和代价。
原则 vs 现实
方案 B 的理论优势(你说得对)
- 单一职责(SRP)—— 每个类只做一件事
- 面向测试 —— 小类好 mock、好单测
- 未来扩展清晰 —— 新成员能快速找到代码
方案 B 在本项目的实际代价
我先看下这个类被多少地方引用: 118+ 处内部自引用,同一个类内 method 相互调用。还有外部调用: 看下外部文件引用:
分析
外部只有 2 个引用点,内部 120+ 个自引用。
方案 B 的真实代价
拆成多个独立 class(如 TapdClient / TapdAIOrchestrator / TapdBindService / TapdWebhookService)后,你会立刻遇到以下问题:
问题 1:循环依赖的噩梦
举个例子:
TapdBindService.handleBindCommand()里调createAndFixBug()→fixBug()fixBug()在TapdBugFixCoreService里fixBug()内部又要调TapdClient.fetchBugDetail()、TapdAIOrchestrator.callAILocate()、发企业微信通知(NotifyService)TapdAIOrchestrator.callAILocate()又要调GitApiService.getRepoTree()
拆出来后:
TapdWebhookService → TapdBindService → TapdBugFixCoreService → TapdAIOrchestrator
→ TapdClient
→ NotifyService
TapdBugFixCoreService → NotifyService
TapdBugFixCoreService → TapdClient
TapdWebhookService → TapdClient(拉 Bug 详情、兜底)
TapdWebhookService → NotifyService(发通知)这个依赖图是个有向无环图,但:
- 每个 class 都要
import3-5 个其他 class - 某些共享的辅助(比如
sendTapdBugFixStatusNotification、buildMentionLine、isFrontendOwner)要么放到一个TapdNotifyService,要么复制多份 - 改一个 method 签名可能要改 3 个文件
问题 2:fixBug 这个核心方法无法拆
fixBug 是整个流程的编排者,700 行代码里调用了:
- TAPD API(拉需求、评论、提测链接)
- AI(locate、fix、resolveRepo、大文件 loop)
- Git API(getRepoTree、getFileContent、createMR、createBranch)
- 通知(各种阶段通知)
- DB(record.save)
拆出子服务后,fixBug 位置无论放哪个类,都会:
- 依赖几乎所有其他子服务
- 每次调用变成
TapdClient.fetchBugDetail(...)而不是this.fetchBugDetail(...)
代码量不会减少,只是分散了。
问题 3:属性私有性丢失
现在 private static readonly FIX_AGENT_ID = '...'、private static callAgent(...) 是私有的。 拆成多个类后,这些要改成 public static 或 export function,封装性反而变差。
问题 4:118 处 TapdBugFixService.xxx 调用全要改
比如现在的:
TapdBugFixService.fetchBugDetail(...)
TapdBugFixService.callAILocate(...)
TapdBugFixService.sendTapdBugFixStatusNotification(...)全变成:
TapdClient.fetchBugDetail(...)
TapdAIOrchestrator.callAILocate(...)
TapdNotifyService.sendTapdBugFixStatusNotification(...)每个方法签名可能变(参数顺序、this 绑定),改点是 118 处,任何一处漏改都可能炸。
方案 A 其实也满足"单一职责"(但边界放在文件层)
方案 A 是文件层面的单一职责,而不是class 层面。
aiCall.ts只做 AI 调用tapdApi.ts只做 TAPD APIwebhookHandlers.ts只做 webhook 解析分发
每个文件都是"一个职责"。方案 A 依然是单一职责原则,只是把"单一职责的单元"从 class 改成了 file + module。
关键洞察
在大量内部耦合的工具类场景下,"拆文件 + 保留统一入口 class" 比 "拆成多个 class" 更合理。
理由:
- 内部调用频繁 → 保留
TapdBugFixService.xxx这种统一调用路径最省心 - fixBug 是编排器 → 它天然要"看得见"所有下游,拆类反而让它成了跨类调度者,更混乱
- 外部只有 2 个引用点 → 零 breaking change 的收益被浪费
- SRP 的粒度是"变化原因" → 这个文件的所有代码都围绕"TAPD Bug 自动修复"这一件事变化,所以整体上它就是单一职责的
什么时候方案 B 才合理?
三种情况:
TapdClient有外部复用 —— 比如另一个业务要直接用 TAPD Open APIAI 调用要抽象成通用服务 —— 比如有 3 个 Agent 编排场景要共享 callAgent- 每个子职责有独立的演进节奏和 owner —— 团队分工明确,不同人维护不同部分
目前这 3 个都不成立。
我的最终建议
坚持方案 A。 它就是"同一个类只做一件事"的合理落地形态,只是把拆分粒度从 class 降到 file。
如果你非常介意"class 层面"的单一职责,我给你方案 A+,介于 A 和 B 之间:
- 保留
TapdBugFixService主类作为门面(Facade Pattern) - 拆出 2-3 个纯无状态辅助模块(不是 class,是 file 导出的 function)
- 主类里调用辅助模块,但对外 API 完全不变
packages/server/src/services/tapdBugFix/
├── TapdBugFixService.ts # 门面 + 核心 fixBug/webhook 编排
├── helpers/
│ ├── aiCall.ts # 独立函数:callAILocate/callAIFix/callAgent 等
│ ├── tapdApi.ts # 独立函数:fetchBugDetail/fetchStory 等
│ ├── responseParser.ts # 独立函数:parseAI*Response 等
│ └── constants.ts # 常量 + PROMPTS + interfaces
└── index.ts # re-export TapdBugFixService这样:
- 主类只剩 ~1000 行,聚焦"业务编排"(fixBug + webhook 路由 + /bind 指令)
- 其他 ~3500 行的"工具型代码"全在 helpers/ 下,彼此无依赖
- 外部调用
TapdBugFixService.fixBug(...)零改动 - 真正符合"同一个类只做一件事" —— 主类只做"TAPD Bug 修复业务编排",不再做 AI 调用细节 / TAPD API 细节 / 解析细节
决策建议
| 目标 | 推荐方案 |
|---|---|
| 快速降低文件行数、最稳 | 方案 A |
| 兼顾 SRP + 稳妥 | 方案 A+(推荐!) |
| 纯理论 SRP,不怕大改 | 方案 B(真的不推荐) |
你要不要我按 方案 A+ 推进?下一步就是第 1 轮:抽 constants.ts(interfaces + SYSTEM_PROMPTS + 类级配置常量),大概能把主文件砍掉 550 行,风险最低,先验证路径可行。
bug 仓库定位
2026-04-22
1. 能在本地用吗
能,现在就能用。 它已经落在 ~/.codebuddy/skills/tapd-resolve-repo-branch/SKILL.md,属于用户级 Skill(location: user),对所有工作区全局可用。
你不用重启 IDE,下次对话里提到"bug 单"、"定位仓库"、"解析提测链接"、给 Bug URL 等关键词时,系统会把它列到 <available_skills> 里,我就能调 use_skill("tapd-resolve-repo-branch") 触发。
顺带一说:当前这一轮对话的
<available_skills>里已经能看到它了(description 就是你刚写的那段)。所以本地生效已经完成。
2. 能在 Knot 智能体上用吗
取决于 Knot 是不是同一套 CodeBuddy Skill 机制,大概率不行。
- 用户级 Skill(
~/.codebuddy/skills/)跟着你本机的 CodeBuddy IDE 插件走。只有在你本机、通过 CodeBuddy 这个 Agent 运行时才能被发现。 - Knot 是独立智能体平台(腾讯内网),它有自己的工具/Skill 注册体系,不会自动扫描你本机的
~/.codebuddy/skills/。 - 如果你希望在 Knot 上复用这套 SOP,需要把
SKILL.md里的内容作为系统提示词 / Prompt 模板 / 知识库条目注册到 Knot 智能体的配置里,并且把resolve.ts脚本包装成 Knot 能调用的工具(HTTP 接口或者 Knot 的 function tool 配置)。
简而言之:Skill ≠ 跨平台通用能力,它是 CodeBuddy 的本地扩展。想跨到 Knot,得走 Knot 自己的那套注册流程。
3. 怎么触发
三种方式,从被动到主动:
| 方式 | 怎么用 | 什么时候用 |
|---|---|---|
| 自动触发 | 在对话里说到 description 里列的关键词(bug 修复、定位仓库、解析提测链接、TAPD bug、bug url 等) | 日常最常见 |
| 显式点名 | 直接说"用 tapd-resolve-repo-branch 这个 skill 处理一下" | 关键词不够明显、想强制走 SOP 时 |
| 斜杠命令(如果 CodeBuddy 支持) | /tapd-resolve-repo-branch | 命令行风格,最快 |
触发后,AI(也就是我)会读到完整的 SOP 文本,按里面的流程调 tapd_mcp_http 工具拉 TAPD 内容 + 调 scripts/tapd-resolve-repo-branch/resolve.ts 脚本解析链接。
4. 怎么更新这个 Skill
直接改 ~/.codebuddy/skills/tapd-resolve-repo-branch/SKILL.md 即可。 下次对话就是新版本,不需要重启、不需要编译、不需要任何注册动作。
如果想改脚本,改 scripts/tapd-resolve-repo-branch/resolve.ts,下次 AI 用 npx tsx 调的时候就是新版本。
常见更新场景:
- 新增一种 Bug 评论格式 → 改 SKILL.md 里"采集内容"那一节
- 新增一种 Git 链接形态(比如 GitLab)→ 改
resolve.ts的正则 - 调整优先级顺序 → 改 SKILL.md 里"排序规则"那一节
5. 怎么"入库"——这才是最关键的问题
你说的"入库",我理解有两层含义:
5.1 本机入库(Git 版本化)
问题:~/.codebuddy/skills/ 在你用户目录下,不在项目仓库里,一换电脑就没了,团队成员也复用不到。
解决方案:在项目仓库里维护一份"源版本",通过软链或同步脚本推到 ~/.codebuddy/skills/。
具体可以这样组织:
tapd-solution/
├── .codebuddy/
│ └── skills/
│ └── tapd-resolve-repo-branch/
│ └── SKILL.md # 源文件,受 Git 管理
├── scripts/
│ └── tapd-resolve-repo-branch/
│ └── resolve.ts # 已经在仓库里了
└── script/
└── install-skills.sh # 同步脚本:ln -s 或 cp 到 ~/.codebuddy/skills/要不要我顺手帮你:
- 把
SKILL.md从~/.codebuddy/skills/搬进 项目.codebuddy/skills/下(项目级可版本化) - 写一个
script/install-skills.sh,团队成员 clone 后跑一次就把项目里的 skills 软链到~/.codebuddy/skills/ - 在 README 的 Skills 沉淀章节加个"如何安装"小节
5.2 团队/组织入库(让同事也能用)
目前看 CodeBuddy 的机制里,Skill 有三层:
- user(
~/.codebuddy/skills/):本人可用 - manager / plugin:系统预置或插件带的,无法自己改
- 项目级(
<workspace>/.codebuddy/skills/,如果 CodeBuddy 支持扫描这里):随仓库走
最稳的办法就是 5.1 的方案——放在项目 .codebuddy/skills/ 下,配合安装脚本。这样:
- 新同事 clone 仓库 → 跑
bash script/install-skills.sh→ 本地立即可用 - Skill 升级 → 改完 commit → 同事 pull → 软链的话立即生效,cp 的话需要重跑脚本
5.3 跨到 Knot / 其他平台入库
这个得看 Knot 具体怎么管理智能体的 Prompt 和工具。一般路径:
- 把
SKILL.md的正文作为 Knot 智能体的系统提示词片段或知识库文档 - 把
resolve.ts包成 HTTP 服务或 Knot function tool - 在 Knot 的智能体编排里把两者串起来
总结一张表
| 问题 | 答案 |
|---|---|
| 本地能用吗 | ✅ 已生效,下一轮对话就能触发 |
| Knot 能用吗 | ❌ 不能直接用,需要改造成 Knot 的 Prompt + Tool |
| 怎么触发 | 关键词自动触发 / 显式点名 use_skill / 斜杠命令 |
| 怎么更新 | 直接改 SKILL.md 或 resolve.ts,下轮对话即生效 |
| 本机入库 | 现在没入库,建议搬到项目 .codebuddy/skills/ + 写安装脚本 |
| 团队入库 | 同上,靠仓库 + 安装脚本 |
| 跨平台入库 | 需要逐个平台按它自己的规范注册 |
支持非 AI Review 的自动修复
2026-04-21
改动说明(handleSlashCommandFix 中一处)
合成虚拟 issue
- 当 DB 里没有匹配到 AI Review issue(
issuesByFile为空)但noteContext.filePath存在时 - 用评论的
filePath/line/parentNoteBody合成一条IReviewIssue塞入issuesByFile - 这样 AI prompt 里会出现结构化的:
### 文件: pixui/.../record.tsx - **[warning]** 来自代码行内评论(非 AI Review):Unexpected space before the ':'. [@typescript-eslint/type-annotation-spacing] 行号: 91
- 当 DB 里没有匹配到 AI Review issue(
指令始终显式带文件+行号
- 原逻辑:有
parentNoteBody就不带filePath/line的 fallback 提示 - 新逻辑:只要
noteContext.filePath存在,就在指令最前面加请修复文件 \xxx` 第 N 行 附近的问题`,再跟上父评论内容
- 原逻辑:有
覆盖场景
| 评论来源 | 修复前 | 修复后 |
|---|---|---|
| AI Review 行内评论 | 精准匹配 DB issue → OK | 精准匹配 DB issue → OK(无变化) |
| ESLint/lint bot 行内评论 | 无结构化 issue,AI 靠猜 | ✅ 合成虚拟 issue + 显式行号 |
| 人工 code review 行内评论 | 无结构化 issue,AI 靠猜 | ✅ 合成虚拟 issue + 显式行号 |
| MR 顶层评论(无 position) | 靠 userInstruction | 无变化(本身就没有文件锚点) |
风险评估
- 对 AI Review 场景零影响(只有在
issuesByFile为空时才合成) - 虚拟 issue 使用
severity: 'warning'/category: 'other',符合现有类型定义 - AI prompt 里
message字段明确标注"来自代码行内评论(非 AI Review)",AI 能理解上下文
mr-auto-fix 集合的主键
2026-04-21
mr-auto-fix 集合的主键
业务主键:Mongo 自动生成的 _id(ObjectId),也就是说每次触发修复都会新增一条独立记录,互不覆盖。
索引设计(见 MRAutoFix.ts 第 143–152 行)
| 索引字段 | 是否唯一 | 作用 |
|---|---|---|
_id | ✅ 主键(Mongo 默认) | 一次修复 = 一条记录,永不覆盖 |
{ projectId: 1, mrIid: 1, createdAt: -1 } | ❌ | 同一 MR 的多次修复按时间倒序排列 |
{ projectId: 1, fixMrIid: 1 } | ❌ | 继续修复流程通过修复 MR iid 反查原始记录 |
{ status: 1 } | ❌ | 按状态筛选/统计 |
{ createdAt: -1 } | ❌ | 列表默认时间倒序 |
{ reviewId: 1 } | ❌ | 按评审记录统计 fixCount 上限判断 |
和原来的区别
旧:MRReview | 新:MRAutoFix | |
|---|---|---|
| 主键 | { projectId, mrIid } 唯一 | _id 自动生成 |
同一 MR 多次 /ai-fix | 覆盖最后一次 | 每次独立一条 |
| 修复方式查询 | 查 MRReview.fixStatus: { $exists: true } | 直接查 MRAutoFix 全表 |
这样你同一 MR 多次 /ai-fix 都能看到完整历史了 —— 也就是上次提的"同一个 mr 多次斜杠命令没有记录"的问题被彻底解决了。
bugOwner
2026-04-18
好消息:代码里其实已经有把 Bug 处理人(bugOwner)加入 MR 的逻辑了(TapdBugFixService.ts 第 858-861 行):
const reviewers = [...TapdBugFixService.DEFAULT_REVIEWERS];
if (record.bugOwner && !reviewers.includes(record.bugOwner)) {
reviewers.push(record.bugOwner);
}但之前的问题是:这个列表只传给了工蜂 API 的 assignee_list(指派人),而不是 reviewer_list(评审人)。在工蜂中这两个是不同的概念:
assignee_list→ MR 的指派人reviewer_list→ MR 的评审人(会收到 Code Review 通知)
修改内容:修改了 GitApiService.ts 的 createMergeRequest 方法:
- 新增可选参数
reviewerList - 如果未单独指定
reviewerList,默认使用assigneeList同时作为评审人 - 创建 MR 时同时传递
assignee_list和reviewer_list
这样 Bug 处理人会同时成为 MR 的指派人和评审人,会收到 Code Review 通知。
小程序组件转 uniapp
2026-03-24
之前一直在做将小程序组件转换为 uniapp 的工作。_example_uni 是用自动转换工具生成的结果,需要把其中新增的组件同步过去。
_example_uni 是用最新的自动转换工具产生的结果,可能有些组件源码有更新(原始小程序版本有改动),这些改动需要同步到已有的 uniapp 版本里。
Claw 个人数字助理
2026-03-13
任何云端智能体都能成为 Claw 吗?
不是。成为 Claw(即个人数字助理)需要满足以下条件:
- 需要有工作区(运行环境):智能体必须绑定一个工作区(AnyDev 容器或本地设备),才能执行文件读写、Shell 命令等操作
- 需要配置 Client 工具:在智能体配置页面启用代码读写工具(Knot CLI),才具备对设备的控制能力
- 需要打通消息端:通过企微机器人、微信等渠道与工作区建立连接
简单说,普通的云端对话智能体(没有绑定工作区和 CLI 工具的)只能回答问题,无法控制设备,不能算 Claw。只有配置了 Knot CLI + 工作区 的智能体,才能实现 Claw 的核心能力
Vibe Coding vs 传统编程
2026-03-11
- 对「编程下限」的影响
传统编程
- 门槛高:语法、环境、逻辑、调试都要学
- 新手容易卡壳、写不出可运行代码
- 下限很低:很多人入门就放弃
Vibe Coding(AI 辅助)
- 自然语言就能生成代码
- 自动补全、纠错、给示例
- 零基础也能跑出可用程序
→ 下限被大幅拉高:几乎人人都能写代码
- 对「编程上限」的影响
传统编程
- 上限 = 你的学习时间 + 经验 + 智商 + 精力
- 普通人很难摸到高上限
Vibe Coding
- 速度、广度、功能复杂度大幅提升
- 能做前后端、小产品、工具、脚本、简单系统
- 上限接近中高级程序员
但到顶就停:
- 架构设计、性能优化、高并发、安全、疑难Bug
- 大型项目、工程化、重构、技术债务
→ 上限到不了顶尖架构师/专家级
- 核心结论
"Vibe Coding 极大提高了普通人编程的下限,也明显拉高了上限,但无法突破真正顶尖的技术天花板。"
- 一句话总结
Vibe Coding 让普通人"会编程"变得极容易,也能做得更快更多,但真正的深度与架构,依然靠人。
Vibe Coding 的局限性
2026-03-11
Vibe Coding 极大提高了普通人编程的下限,也明显拉高了上限,但无法突破真正顶尖的技术天花板。
- AI 生成代码常缺架构、性能、安全、异常处理、高并发能力。
- 复杂系统、底层优化、疑难 Bug、大规模工程,仍依赖深度编程理解。
- 项目变大后,维护、重构、技术债务会剧增。
OpenClaw 与数据主权
2026-03-10
2026 年,AI Agent 领域迎来爆发式增长。然而,当越来越多的用户开始将个人数据、工作文档、日程安排托付给 AI 助手时,一个尖锐的问题浮出水面:我的数据去哪了?
传统 AI 助手几乎清一色采用云端架构——你的聊天记录、文件内容、行为偏好,统统上传到厂商服务器。用户在享受便利的同时,也在不知不觉中出让了最宝贵的东西:数据主权。
正是在这样的背景下,OpenClaw 凭借其"Local First"(本地优先)的核心理念横空出世,给出了一个截然不同的答案:AI 可以很强大,但你的数据必须留在你自己手里。
MCP 与 Function Calling 的关系
2026-03-06
所以本质上 MCP 就是借助 Function Calling 的机制,对外提供一个服务,让既有的系统快速集成到 LLM 中,通常一个 MCP Server 有很多工具,而不是一种。
那 MCP 跟 Function Calling 是什么关系呢?这是网上大多数文章都有问题的地方,它们是协作关系!我们简单叙述一下流程:
- 第一阶段:能力构建与协议初始化(前提条件)
- 大模型的微调 (Foundation):通过微调使 LLM 获得核心能力,也就是能理解 MCP 标准的格式化请求。这个本质上跟训练如何识别 Function Calling 是一样的,所以有人说 MCP 就是基于 Function Calling 的。
- MCP 动态注册 (MCP Registration):AI Agent 启动的时候,同时会启动在 Agent 里的 MCP client 客户端,MCP Client 客户端回拿到的数据返回给 AI Agent,然后 AI Agent 根据之前大模型训练好的如何接收 MCP 标准的格式化请求的要求,将这些动态获取的工具定义会随用户问题一起注入大模型
- 第二阶段:实际运行与协议化调用
- 用户提问 (Query):后续用户发起请求给 AI Agent
- 注入与识别:Agent 将"用户问题"与"从 MCP Server 拿到的工具定义"一并下发给 LLM
- 意图识别与决策:LLM 匹配工具集,识别出调用需求,输出符合 MCP 协议的指令,例如:call:
- 路由解析与分发:Agent 中枢解析指令,通过 MCP 客户端 将执行请求精确路由至对应的 MCP 服务器。
- 协议化执行:MCP Server 在其编程上下文(如本地数据库、Python 环境或 HTTP 远程服务)中执行函数。
- MCP Client 将返回的结果再次返回给 AI Agent, Agent 将获取的数据再次请求大模型, 最终返回给用户结果。
嵌入与向量
2026-03-06
你可以把"嵌入"理解为:给每一个词画一张极其精细的"多维画像"。
此时向量这个出现在很多科普文章中关键概念出现了,我会用更通俗易懂的方式来解释。举例:描述一个人,可以用四个维度:[性别(0是女生,1是男生), 身高, 体重, 年龄]
"男人" → [1, 175, 70, 30]
"女人" → [0, 165, 50, 25]
这里的 [1, 175, 70, 30] 在数学上就叫 向量(Vector)。而把"男人"这个词映射到这串数字的过程,就叫 嵌入(Embedding)。
核心思想:在数学空间里产生"思维"
如果 4 个维度能描述一个人,那么大模型会用成千上万个维度(比如:褒贬、生命体、具体/抽象、科技术语等)来给每一个词画画像。
当所有的词都被打分并转化成"嵌入向量"后,神奇的事情发生了:这些词不再是孤立的符号,而是变成了多维空间里的一个点。
在这个数学空间里:
- 距离代表关系:意思相近的词(如"开心"和"快乐"),它们的画像数字非常接近,在空间里的距离也极短。
- 逻辑可以计算:因为每个词都是一组数字,它们竟然可以像加减法一样运算。
科学家们发现了一个震惊世界的现象:
"国王"的向量 - "男人"的向量 + "女人"的向量 ≈ "女王"的向量
换句话说:"嵌入"技术不仅把文字变成了数字,还把文字背后的逻辑关系也一并平移到了数学世界里。这是大模型能够"思考"的物理基础。
AI 时代的三个认知
2026-02-26
第一,最好的模型就是这个时代最大的信息差,从花费20刀开始。无论国内多少炸场、掀桌子、炸榜。目前最好的AI工具还是国外三巨头,这不是工具便好,而是认知分流,时间区间拉长,用谷歌的人认知大概率比百度的高、用ChatGPT、Claude、Gemini大概率比用其他的高。
第二,打破认知防御。不要当评委,当教练。给AI你的完整context——你的知识、你的标准、你的判断逻辑。你给得越多,它越像你的延伸。不是用工具,是在训练一个懂你的分身。
第三,与AI迭代加速度赛跑。AI能做的事价值在归零。问自己:我有什么是AI做不了的?不是学历,不是年限。是三样东西:你有而AI没有的一手经验、你对问题比AI更深一层的洞察、AI想不到的解法。
但这里有个悖论——你不深度用过AI,就不知道它的边界在哪。你不知道它的边界,就找不到自己真正的壁垒。
ti18n-mcp
2026-02-12
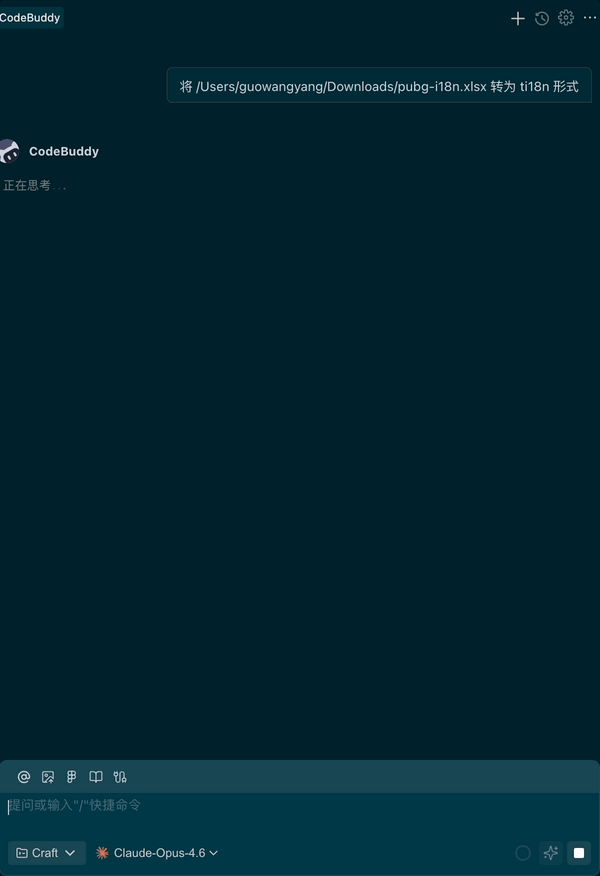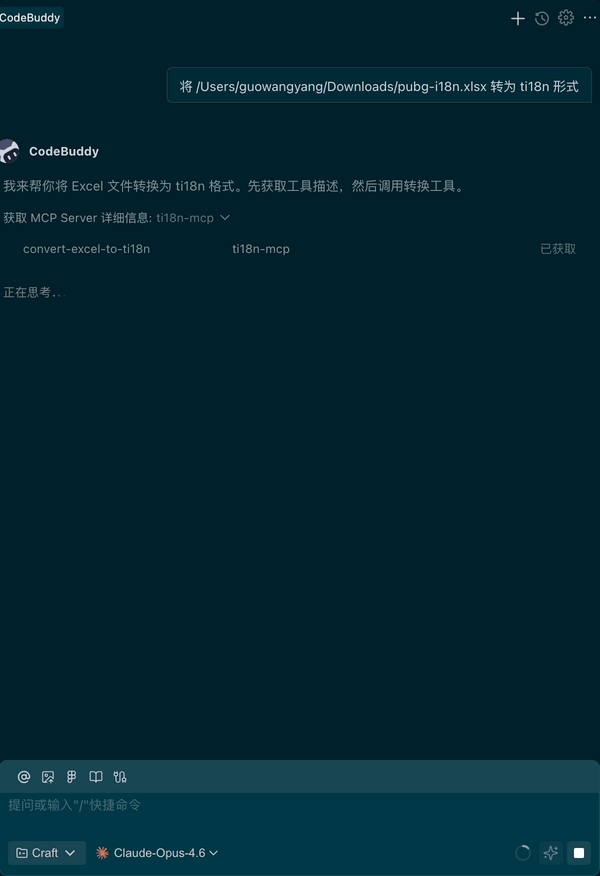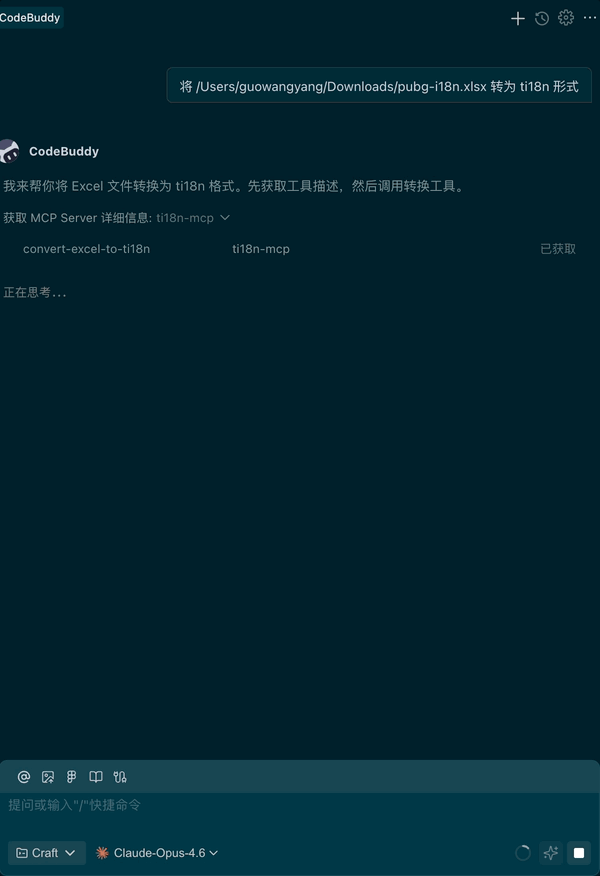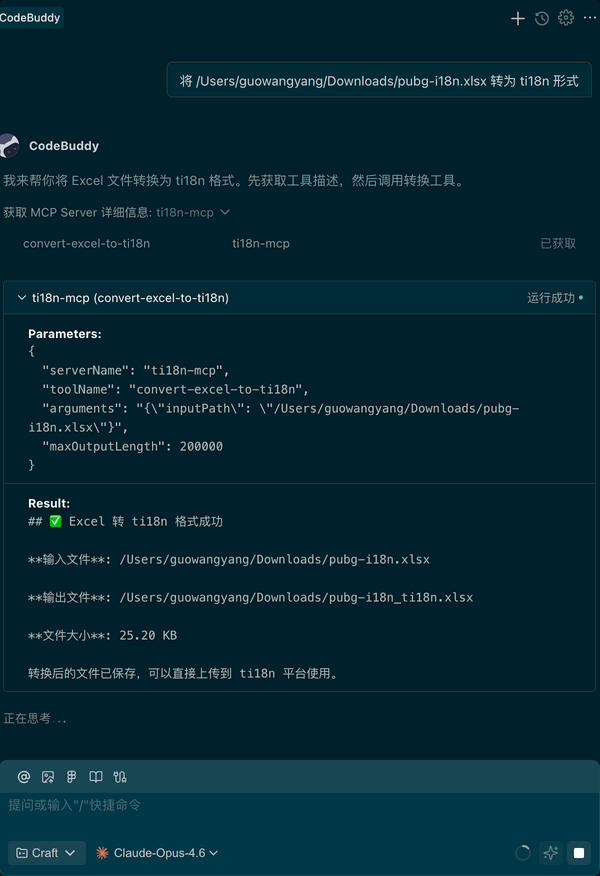
ti18n-mcp
CodeBuddy MCP 文档
2026-02-10
https://www.codebuddy.cn/docs/cli/mcp
算力即生产力
2026-02-10
算力就是生产力。算力的富足将我们带入计算时代。算力重新锚定了科技创新的坐标。
模型训练与推理
2026-02-09
- 模型训练过程就是不断前向传播、损失计算、反向传播、参数更新的过程。
- 模型推理就是根据训练好的参数,进行前向传播的过程。
支持向量机 SVM
2026-02-06
支持向量机(Support Vector Machine,简称 SVM)是一种强大的分类算法,在数据科学和机器学习领域广泛应用。SVM 的核心思想是,找到一个最优的决策边界,或者称为"超平面",这个边界能够以最大的间隔将不同类别的数据分开。这里有几个关键点需要好好理解一下。
超平面:在二维空间中,这个边界就是一条线;在三维空间中,是一个平面;而在更高维度的空间中,我们称之为"超平面"。这个超平面的任务就是尽可能准确地分隔开不同类别的数据点。
最大间隔:SVM 不仅仅寻找一个能够将数据分类的边界,它寻找的是能够以最大间隔分开数据的边界。这个间隔是指不同类别的数据点到这个边界的最近距离,SVM 试图使这个距离尽可能大。直观上,这样的边界更能抵抗数据中的小变动,提高模型的泛化能力。
支持向量:决定这个最优超平面位置的几个关键数据点被称为支持向量。它们是最靠近决策边界的点,实际上这个最大间隔的边界就是通过这些点来确定的。
核技巧:当数据不是线性可分时,也就是说无法通过一个直线或平面来分隔,SVM 可以利用所谓的核技巧将数据映射到一个更高维的空间,在这个空间中数据可能是线性可分的。这使得 SVM 在处理非线性数据时非常强大。
简单来说,你可以将 SVM 想象成一个尽可能在不同类别间画一条粗的、清晰的界线,而这条界线是由距离它最近的几个点(支持向量)决定的。这种方法使得分类决策不仅仅依赖于数据的分布,而且具有很好的泛化能力,能够应对未见过的新数据。
SVM 核心思想
2026-02-06
SVM 的核心思想是,找到一个最优的决策边界,或者称为"超平面",这个边界能够以最大的间隔将不同类别的数据分开。
Prompt 六要素
2026-02-04

任务、上下文、范例、角色、格式、语气
提示工程师
2026-02-04

提示工程师
Robot 子 Agent 系统
2026-02-03
✅ Robot 子 Agent 系统已完成
已经重新检查并确认了整个系统结构完整。以下是文件结构和功能说明:
📁 文件结构
src/next-admin-svr/robot/
├── index.ts # 模块导出入口
├── types.ts # 类型定义
├── orchestrator.ts # 编排器(核心调度)
└── agents/
├── index.ts # Agents 导出入口
├── intent-recognition-agent.ts # 意图识别 Agent
├── project-search-agent.ts # 项目搜索 Agent
└── publish-agent.ts # 发布 Agent🔄 工作流程
🎯 各 Agent 职责
| Agent | 职责 | 实现方式 |
|---|---|---|
| IntentRecognitionAgent | 解析用户意图 | 正则匹配 + AI(@tencent-ai/agent-sdk) |
| ProjectSearchAgent | 模糊匹配项目 | 数据库查询 + 评分算法 |
| PublishAgent | 执行发布操作 | 调用 mcpPublish |
💬 支持的命令
1. 发布 <项目名> [分支名] [发布原因]
例: 发布 gp-next develop
例: 发布 gp-next release 修复bug
2. 查询 <项目名>
例: 查询 gp-next
3. 帮助 / help🔌 集成方式
路由文件 robot.ts 已集成:
import { RobotOrchestrator } from '../robot';
const orchestrator = new RobotOrchestrator({
useAI: true, // 启用 AI 意图识别
});
router.post('/', async (req, res) => {
const response = await orchestrator.handleMessage(messageText, {
staffname,
messageId: req.body.msgid,
});
res.send(response);
});📝 扩展新功能
后续要添加新功能,只需:
- 定义新的意图类型:在
types.ts的IntentType枚举中添加 - 创建新的 Agent:在
agents/目录下创建新的 Agent 类 - 注册到编排器:在
orchestrator.ts中添加处理流程
例如,添加"回滚"功能:
// 1. types.ts
export enum IntentType {
// ...
ROLLBACK = 'rollback', // 新增
}
// 2. agents/rollback-agent.ts
export class RollbackAgent implements IAgent<RollbackParams, RollbackResult> { ... }
// 3. orchestrator.ts handleMessage 中添加 case
case IntentType.ROLLBACK:
return this.handleRollbackFlow(intent, context);CodeBuddy 输出内容替换
2026-02-01
codebuddy 中的输出内容需要替换
第1步
command:gongfeng[^)]+ 替换为第2步
\[([^]+?)\]\(\) 替换为 $1